【コラム】AIを使ってIPOの初値を予測する
- 2021/7/14
- 初めてのIPO
IPOの初値を予想するには、事業の内容やIPOの規模、価格設定などから予想していくことになりますが、必ずしも適正な初値水準というのがあるわけではありません。過去に上場した類似のIPOの初値は参考値として有用ではありますが、それでも全く同じ条件のIPOは存在しません。
ここでは、過去のIPOの初値データをもとに、「AI(機械学習)」を利用して、初値の予測モデルを構築していきます。
1AIと機械学習
AIを使って予測モデルを構築する前に、簡単にAIについて確認しておきましょう。
AIとは
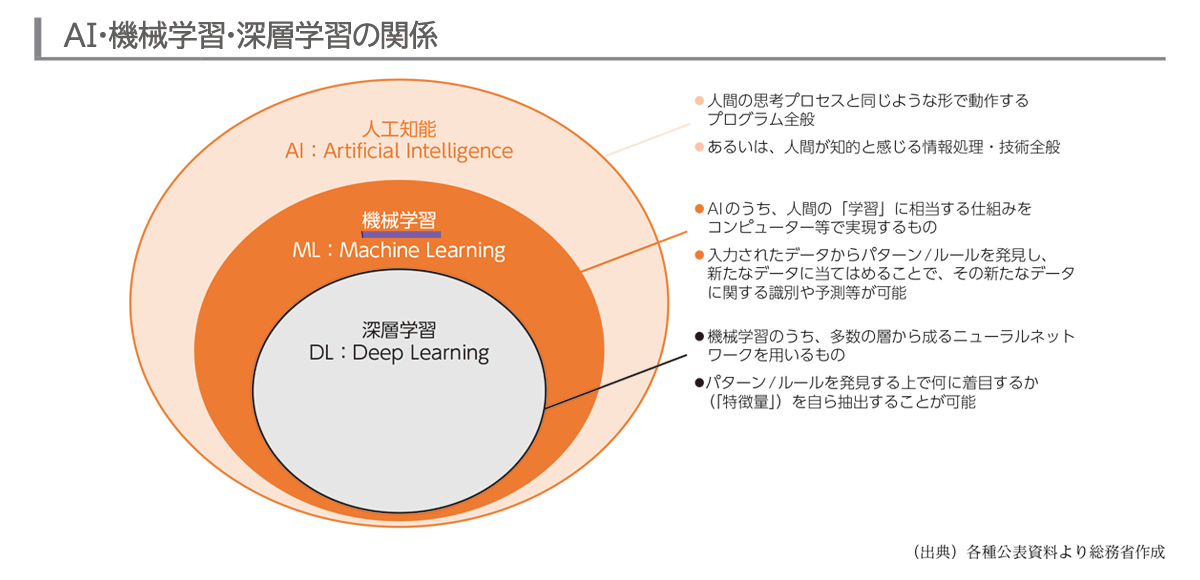
AIは「Artificial Intelligence(アーティフィシャル・インテリジェンス)」の略で、日本語では「人工知能」と訳されます。一般的に、人間と同じように学習や認識、判断するようなコンピューターのことを指す場合が多いですが、明確な定義があるわけではありません。
また、AIを語る上でよく使われる言葉に「機械学習(Machine Learning)」があります。機械学習は、データから一定の規則(パターン)や法則(ルール)を、コンピュータ自身が抽出する技術のことをいいます。つまり、AIは広義の概念であり、機械学習はAIが稼働するための必要な要素の1つといえます。
機械学習の種類
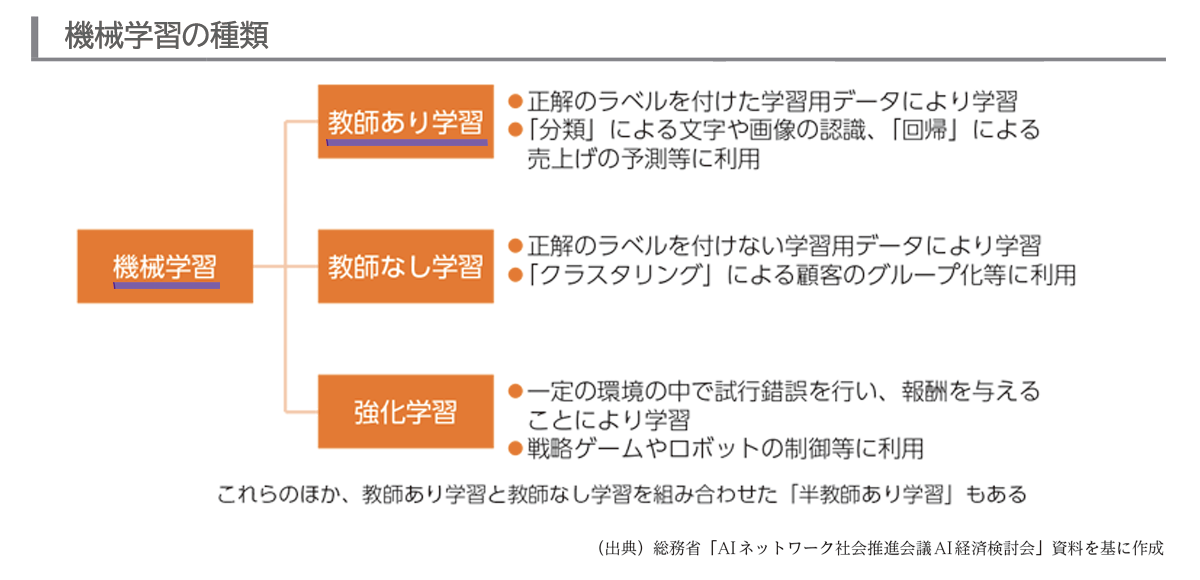
機械学習では、データから規則性や判断基準を学習し、それに基づき未知のものを予測、判断していくことになります。また、機械学習には、「教師あり学習」「教師なし学習」「強化学習」の3種類の方法があります。
IPOの初値を予測するモデルでは、特に「教師あり学習」で分析を進めていくことになります。
2予測モデルの構築
今回は機械学習のオープンソースライブラリである「scikit-learn」を使用してモデルを構築していきます。scikit-learnは、Pythonの機械学習ライブラリで、誰でも無料で利用することができます。また、プログラムを実行するツールとして、機械学習ではおなじみの「Jupyter Notebook」を利用します。
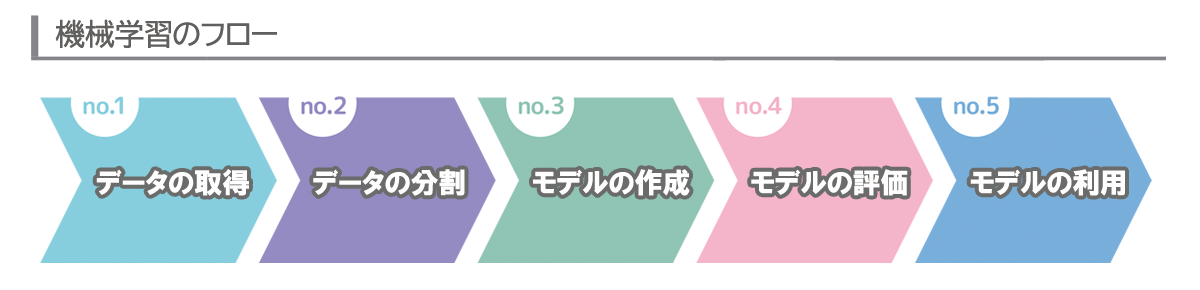
データ解析と予測については、大きく5つのステップに分けて進めていきます。
データの取得
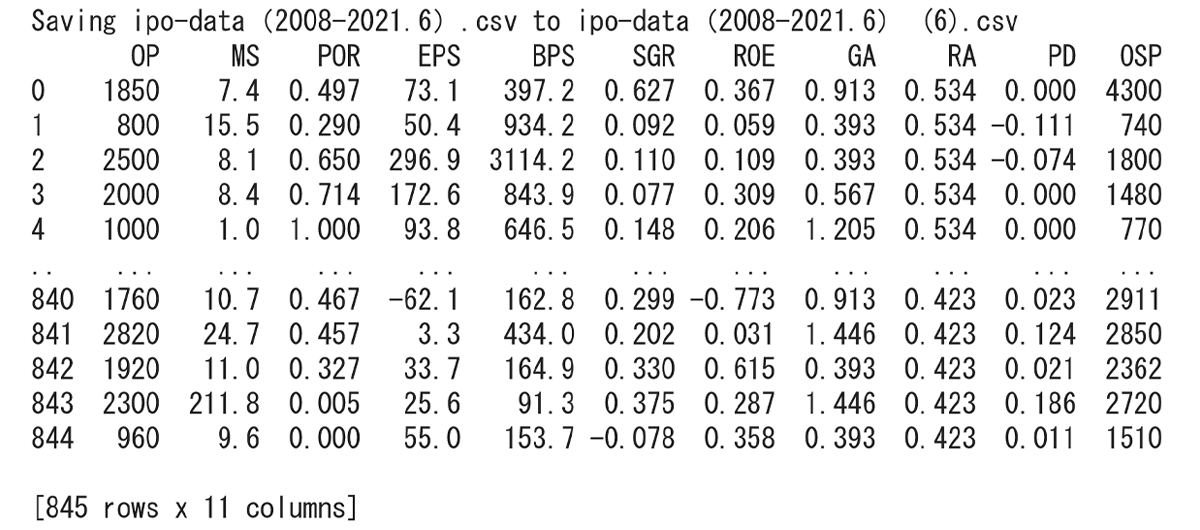
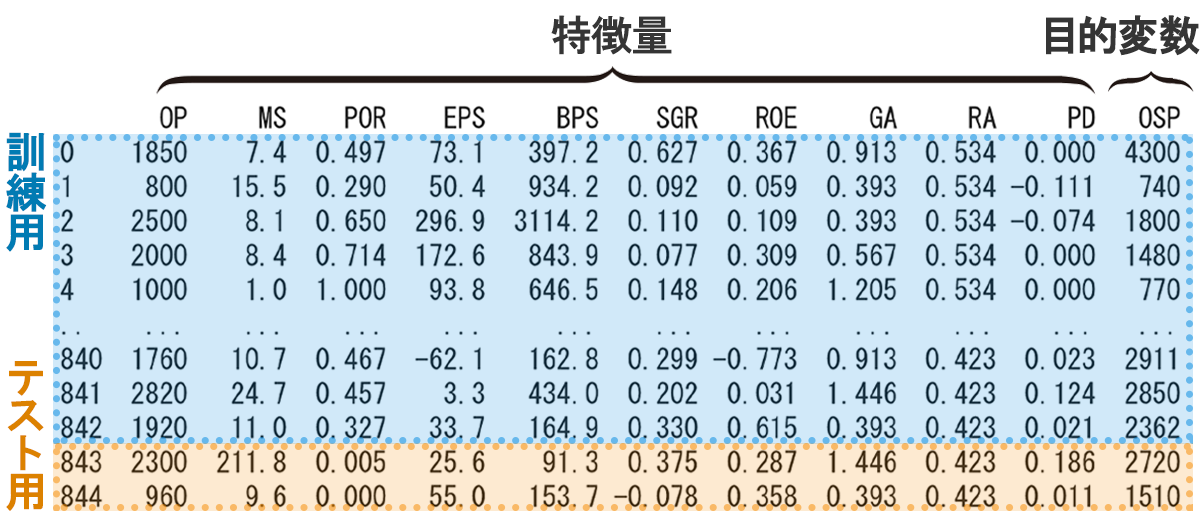
今回使用するデータは、2008年1月から2021年6月の間に上場した企業の初値データ890件のうち、初値騰落率が全体の平均から2σ(標準偏差の2倍)以上離れた45件を除く、845件のデータとしました。また、データの中身は、以下の構成としています。
| データ | 説明 |
|---|---|
| OP | 公開価格(円)※上場時の単元数は100株に統一 |
| MS | IPO規模(投資家の資金供給額(億円)) |
| POR | 募集株数における公募株数の割合(%) |
| EPS | 1株あたり利益(円) |
| BPS | 1株あたり純資産(円) |
| SGR | 直近の売上高成長率(%) |
| ROE | 直近の自己資本利益率(%) |
| GA | 類似グループの平均初値騰落率(%) |
| RA | 直近(上場承認日時点)の平均初値騰落率(%) |
| PD | 想定価格と公開価格の乖離率(%) |
| OSP | 初値(円) |
これらのデータをJupyter Notebookにインポートします。
- # データをインポート
- import pandas as pd
- import io
- df = pd.read_csv(io.StringIO(uploaded[‘ipo-data(2008-2021.6).csv’].decode(‘utf-8’)))
データの分割
インポートしたデータについて、目的変数と特徴量を定義します。今回予測したいデータは初値になるので「OSP」が目的変数、それ以外が特徴量となります。また、845件のデータを訓練用とテスト用のデータに分割します。今回は、それぞれ8:2の割合で分割しています。
- # 変数の組み合わせ
- X_train = train[[“OP”,”MS”,”POR”,”EPS”,”BPS”,”SGR”,”ROE”,”GA”,”RA”]]
- Y_train = train[“OSP”]
- X_test = test[[“OP”,”MS”,”POR”,”EPS”,”BPS”,”SGR”,”ROE”,”GA”,”RA”]]
- Y_test = test[“OSP”]
- # 訓練用とテスト用に分割
- from sklearn.model_selection import train_test_split
- train, test = train_test_split(df,test_size=0.2,random_state=100)
モデルの作成
機械学習のモデルには、重回帰やランダムフォレストなど、いろいろな学習モデルがありますが、ここでは、複数のモデルを融合させて1つの学習モデルを生成する「アンサンブル学習」で予測モデルを作成していきます。今回は、XGboost、ランダムフォレスト、重回帰の3つのモデルのアンサンブルで学習を行います。なお、学習で使うデータは訓練用のデータになります。
- # モデルの作成
- reg1 = xgb.XGBRegressor(colsample_bytree=1.0,eta=0.01,gamma=1,max_depth=7,min_child_weight=1,subsample=0.8)
- reg2 = RandomForestRegressor(random_state=1,n_estimators=100)
- reg3 = LinearRegression(normalize=True)
- ereg = VotingRegressor(estimators=[(‘xgb’,reg1),(‘rf’,reg2), (‘lr’,reg3)])
- ereg = ereg.fit(X_train, Y_train)

モデルの評価
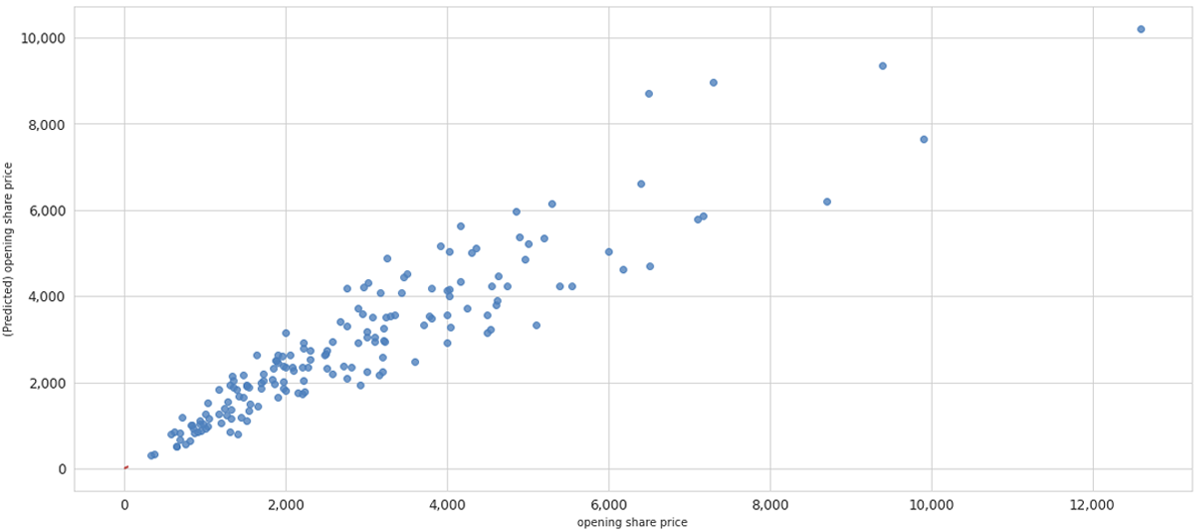
作成したモデルについて、テスト用のデータを使って予測精度を評価していきます。ここでは、決定係数(R2)と平均誤差率を計算します。なお、決定係数は、0〜1の範囲の値をとり、値が1に近いほど予測精度が高いモデルということになります。結果を見ると、訓練用データの決定係数は93.7%、テスト用データでは84.5%と乖離は小さく、予測モデルとしてはまずまずの精度といえます。また、この予測モデルの誤差率は18.6%となっています。
- # 評価指標
- yhat_test = model.predict(X_test)
- return
- “adjusted_r2(test):” + str(adjusted_r2(X_test,Y_test,model)),
- “平均誤差率(test):” + str(np.mean(abs(Y_test / yhat_test – 1)))

また、テスト用データを使って、実際の初値とモデルが予測した初値がどれほど一致しているかグラフでも確認してみます。(横軸:実際の初値、縦軸:モデルが予測した初値)
- # グラフ描画
- plt.figure()
- ax = sns.regplot(x=Y_test, y=ereg.predict(X_test), fit_reg=False,color=’#4F81BD’)
- ax.set_xlabel(u”opening share price”)
- ax.set_ylabel(u”(Predicted) opening share price”)
- ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ‘,’)))
- ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ‘,’)))
- ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color=”#C0504D”,ls=”–“)
モデルの利用
最後に、構築したモデルをもとに2021年7月に上場予定のランドネットの初値を予測してみます。なお、予測時点で公開価格が決定していない場合は、想定価格と公開価格は同じ価格とみなして予測します。
- # 初値予測の実行
- submission = pd.DataFrame({
- ‘Prediction(OSP)’: ereg.predict(X_df2)})

今回構築したモデルによると、ランドネットの初値は5,510円と予測されました。